F2:AI 必知必会(二)—— AI Agent 全景图
本期是所有学员的共同起点。无论你是产品经理、开发者、还是 AI 爱好者,这节课的内容会成为后续所有模块的认知基础。
WARNING
🧪 Beta 公测版本提示:本节课程主体已完成,正在优化细节。
欢迎大家提 Issue 反馈问题或建议,也欢迎大家提 Pull Request 参与课程共建。
本期课程简介
我们将为大家展示并介绍 AI Agent 的完整图景 —— 通过一张地图,把 Memory(RAG) 和 Tools(Skill、MCP) 放到正确的位置上,看清它们的关系。
并带大家一起去理解这张地图上的每一项能力,底层都和数据有着什么密切的关系。
一个思考题
上一期课程中,我们提到了一个非常核心的公式 —— AI 的能力上限 = 模型能力 × 数据质量。
这个公式在大模型对话场景里已经被反复验证过了,那这期课程我们想跟大家探讨一个问题:这个公式到了智能体时代,还适用吗?
我们的回答是 —— 依然适用,但需要扩展。
因此,我们给出了一个扩展版本:
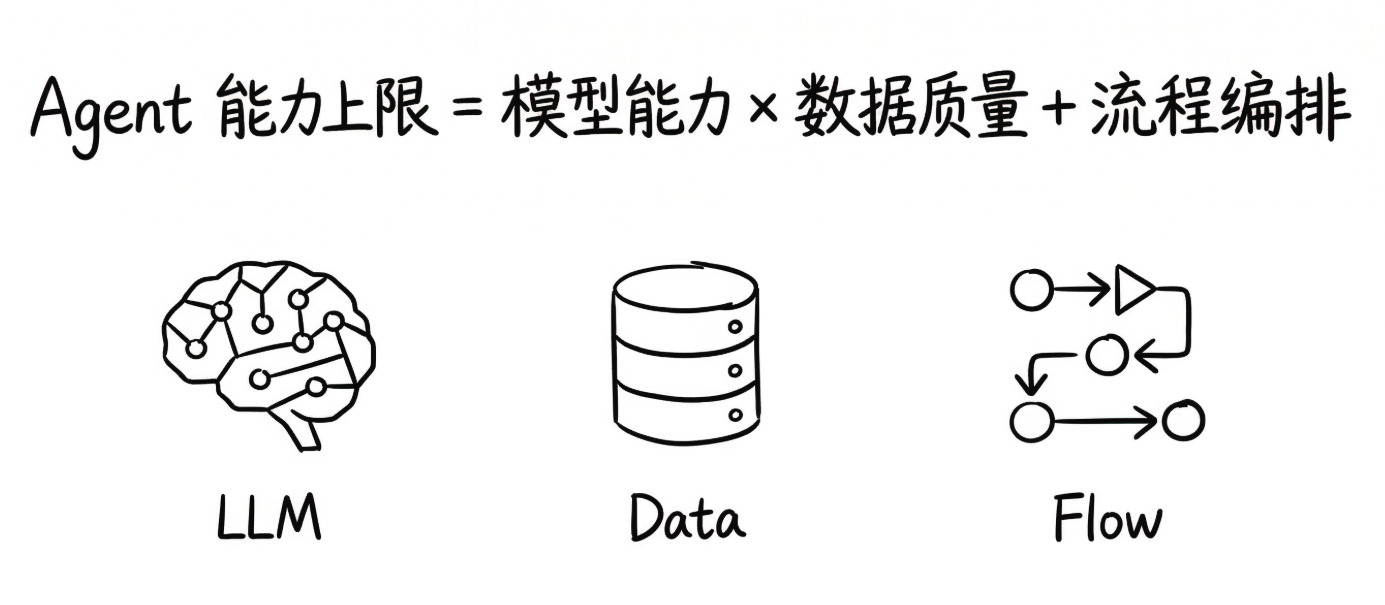
AI Agent 的能力上限 = 模型能力 × 数据质量 + 流程编排。
注意这里的符号:乘号与加号的区别至关重要。
· 乘号(Data × LLM):决定能力的基础量级,是核心驱动力
· 加号(+ 流程编排):在基础之上的优化增量,是锦上添花
本节课将深入解析这个公式背后的逻辑,以及为什么 Data 依旧是 Agent 能力的核心决定因素。
上面这个新公式中,为什么要加上流程编排?
这个“加号”意味着什么?
别急,我们一步一步来,先从最基础的问题说起 —— 什么是 Agent 智能体?
从 ChatGPT 到 Agent 的跨越
你很可能已经用过 ChatGPT、千问、豆包等基于大模型的 AI 助手。它们很聪明,能写文章、改代码、回答问题。
但你有没有注意到,它们都有一个共同的局限:每次对话都是从零开始。
- 你问它“帮我分析一下这份数据”,它会说“请把数据发给我”
- 你问它“上次你推荐的那个方案效果怎么样?”,它会说“我不记得上次的对话”
- 你问它“帮我查一下公司内部文档”,它会说“我无法访问你的文档”
这些工具很强大,但它们本质上是 “无状态的对话机器人” ——没有记忆、没有知识库、没有工具调用能力。
AI Agent 就是要突破这些限制。
Agent 不是“一个更聪明的 ChatGPT”,而是一个具有“感知 → 推理 → 行动” 循环能力的系统:
- 它能查资料(RAG)
- 它能记住你(Memory)
- 它能调用工具(Skill)
- 它能连接外部世界(MCP)
这节课,我们要建立一张完整的 Agent 能力地图,看清这些概念的相互关系——以及它们共同的数据本质。
概念核心
Agent 的本质:感知 → 推理 → 行动
行业对 Agent 最经典的定义来自 OpenAI 研究员 Lilian Weng 在 2023 年发表的博文《LLM Powered Autonomous Agents》。
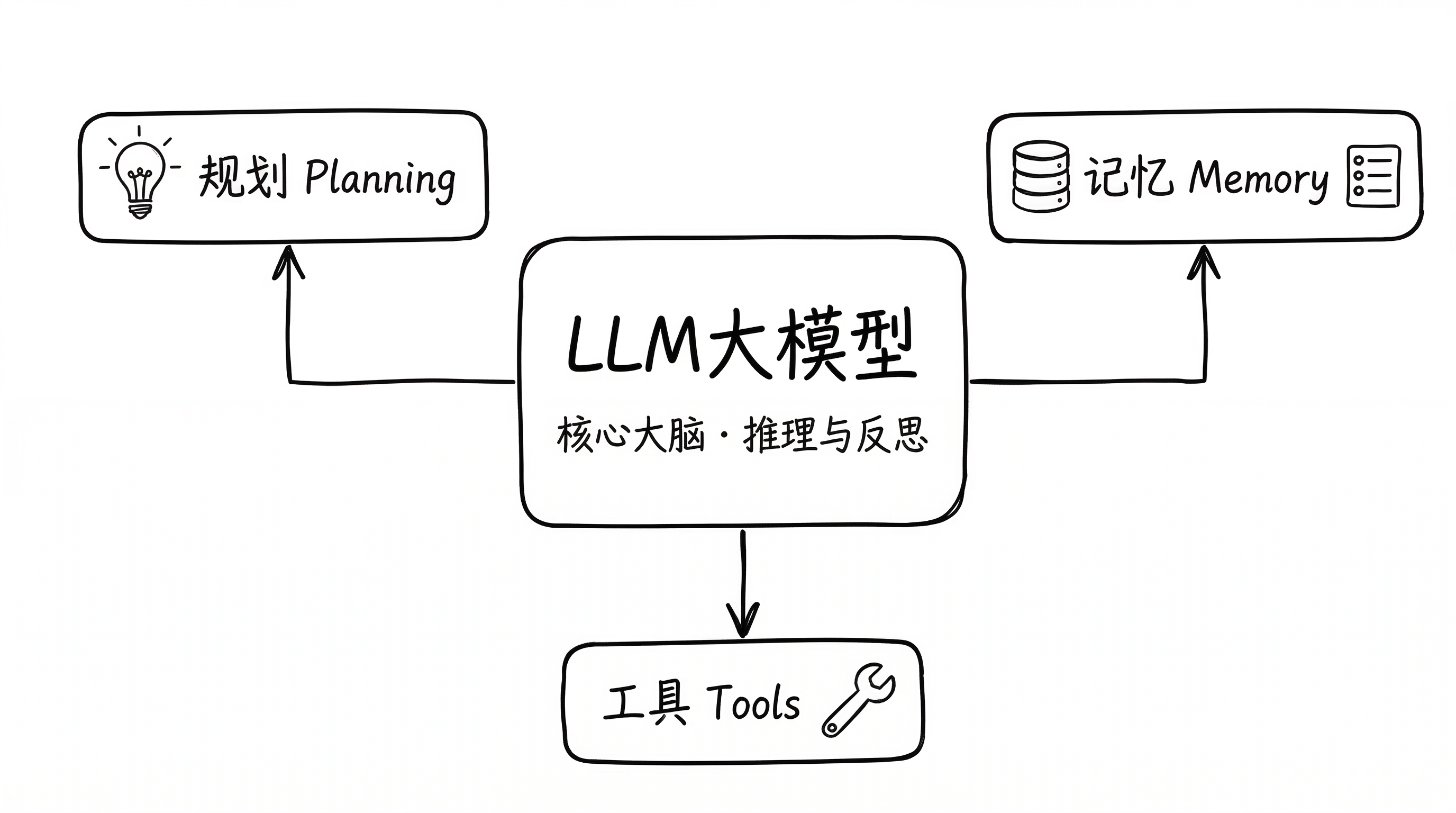
核心架构包含四个组件:
- Memory(记忆系统) - 存储与召回历史交互和用户偏好
- LLM(大语言模型) - 作为核心大脑,负责推理与决策
- Planning(规划能力) - 制定任务分解与执行策略
- Tool Use(工具调用) - 连接外部数据源与执行能力
基于以上四个组件,AI Agent 的运行模式是:感知 → 推理 → 行动 → 观察 → 继续推理。
这是一个循环迭代的过程,而非传统 AI 对话的单次响应模式。
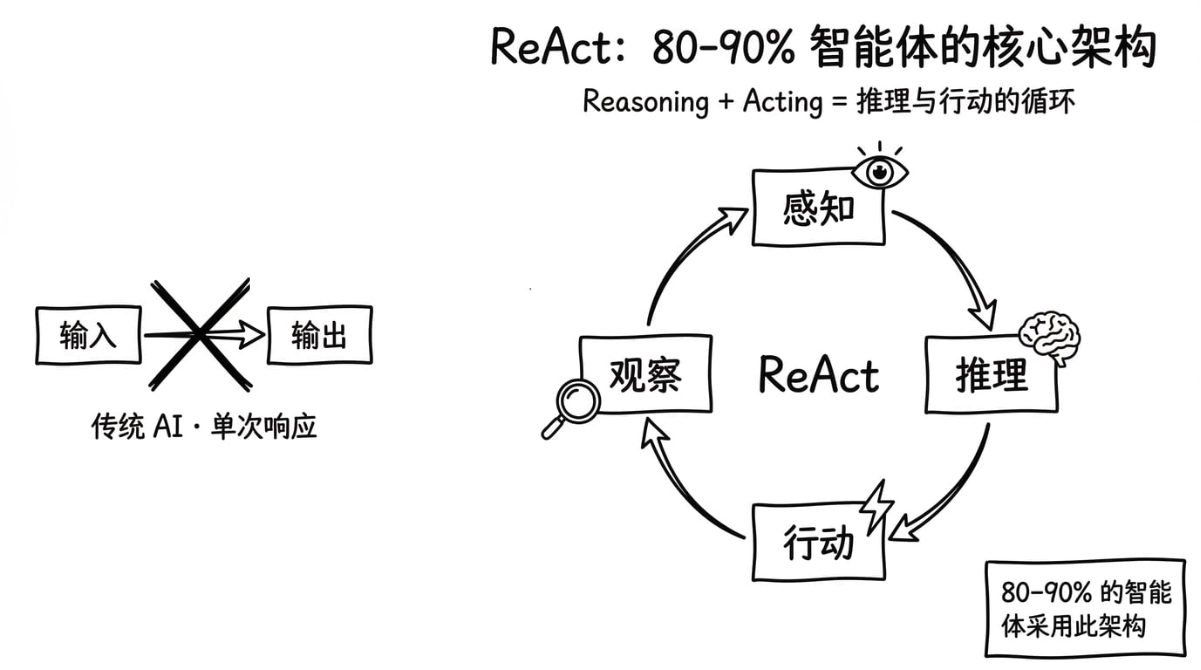
传统的 AI 对话流程是这样的:
用户输入 → 大模型生成 → 返回结果这是一个单次响应的模式,模型看到你的问题,直接生成答案。
Agent 的工作方式完全不同:
推理(Reason)→ 行动(Act)→ 观察(Observe)→ 继续推理...为了方便大家理解,我们举个例子:
用户说:“帮我查一下上个月的销售数据,并分析增长原因”
Agent 的思考过程:
推理:“我需要先查询销售数据”
行动:调用数据库查询工具
观察:拿到了数据“10 月销售额 100 万,11 月 120 万”
推理:“增长了 20%,我需要查一下这期间的营销活动”
行动:查询营销记录
观察:发现“11 月有双十一促销”
推理:“现在信息足够了,可以给出分析”
行动:生成最终报告……
看到了吗?Agent 不是一次性生成答案,而是在 “推理-行动-观察” 的循环中逐步完成任务。
这很明显是一个循环迭代的过程,这个推理 - 行动的循环,行业里用得最广泛的架构叫 ReAct。 ReAct 这个词拆开就是 Reasoning + Acting,先推理再行动。
用一组数据让大家更直观地感受:目前行业里 80% 到 90% 的智能体,用的都是 ReAct 架构。
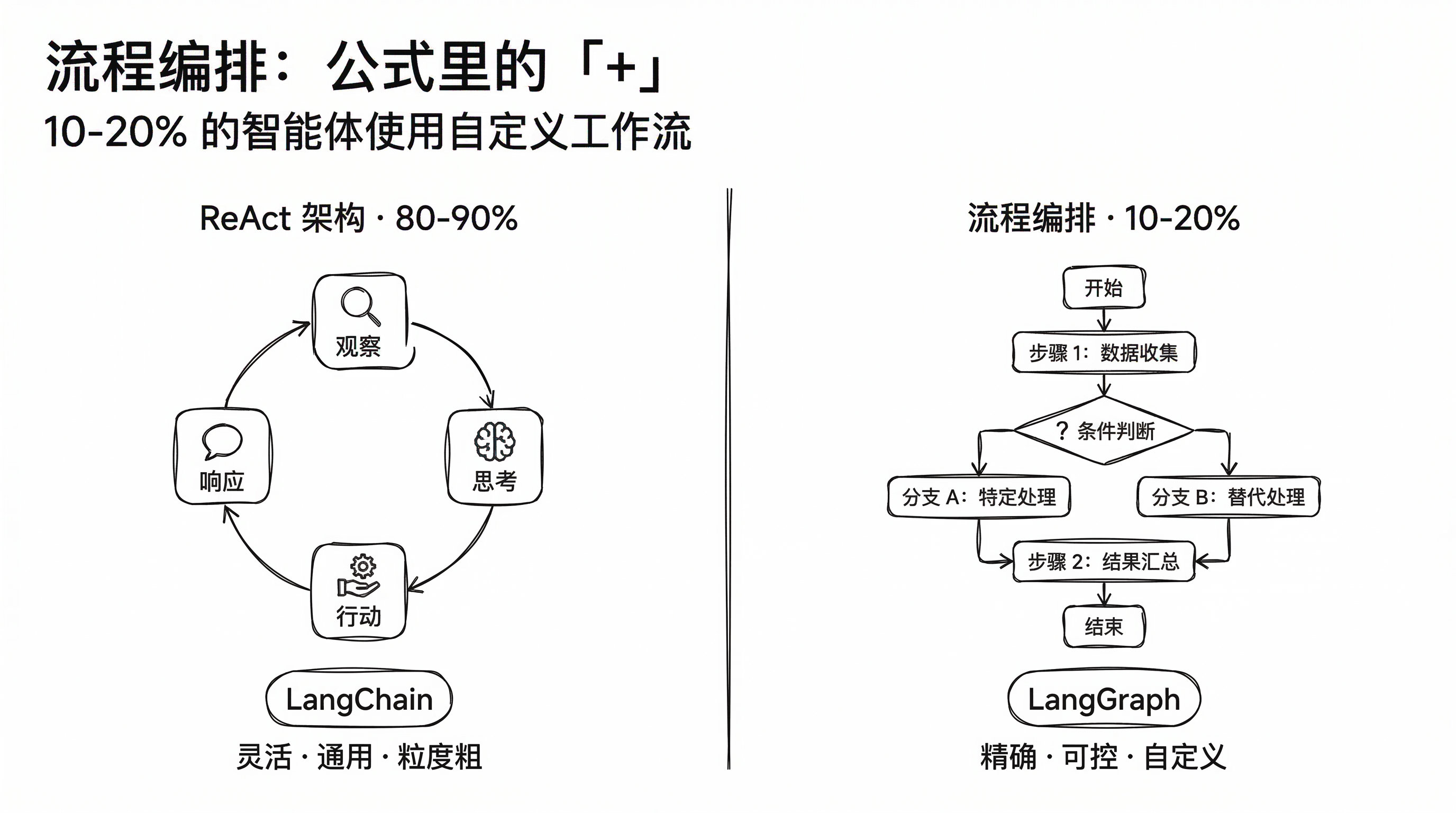
ReAct 架构(占比 80% - 90%)
ReAct(Reasoning + Acting)是目前行业最广泛采用的 Agent 架构模式。
核心特点:
- 交替进行推理(Reasoning)与行动(Acting)
- 模型自主决定何时调用工具、何时返回结果
- 灵活性高,适用于开放式任务
代表实现:
- LangChain 的默认 Agent 实现
- OpenAI 的 Function Calling 模式
- 大部分商业 Agent 产品
流程编排架构(占比 10% - 20%)
通过预定义的工作流(Workflow)将多个步骤按特定顺序和条件串联。
核心特点:
- 显式定义节点(Node)与边(Edge)
- 支持条件分支、循环、并行执行
- 可控性强,适用于固定流程任务
代表实现:
- LangGraph (LangChain 的底层编排框架)
- Dify 的工作流模式
- 企业级 RPA + AI 混合方案
为什么核心仍是 Data × LLM
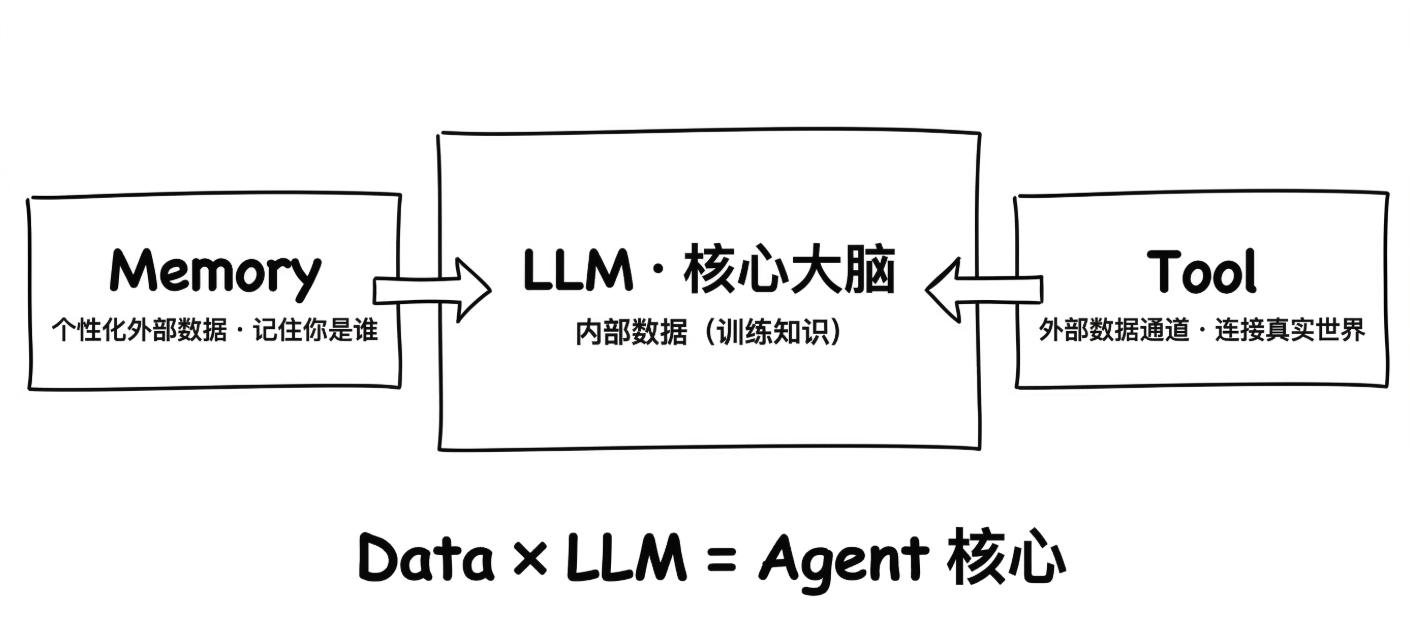
回到 Lilian Weng 的架构图,我们会发现一个关键事实:
图的正中心是 LLM —— 大模型是整个 Agent 的核心大脑。
- 负责所有推理与反思
- 携带海量内部数据(预训练知识)
图的两侧是 Memory 与 Tool——它们都在为大模型提供外部数据。
- Memory:提供个性化数据(用户偏好、历史交互)
- Tool:提供实时数据(数据库查询、API 调用、文件读取)
Agent 的核心运转,归根结底是 Data 与 LLM 的协同:
- LLM 决定 Agent 能“想多好”(推理能力上限)
- Data 决定 Agent 能“做多好”(执行效果上限)
经典原则: Garbage In, Garbage Out(数据质量是 AI Agent 的命门)。
无论模型多强大,如果输入的数据质量低劣、检索策略错误、上下文不完整,输出结果必然不可靠。
流程编排的定位:流程编排解决的是“怎么走”的问题,Data × LLM 解决的是“能走多远”的问题。流程编排能提升稳定性与可控性,但无法突破数据与模型的能力边界。
大模型是 Agent 的推理核心,但**感知和行动需要外部能力支撑 **—— 这就是接下来要讲的四类能力。
AI Agent 地图速览 —— RAG / MCP / Skill 分别是什么?
有了上面这个认知基础之后,我们来聊聊现在行业里的几个热词 —— RAG、MCP、Skill。
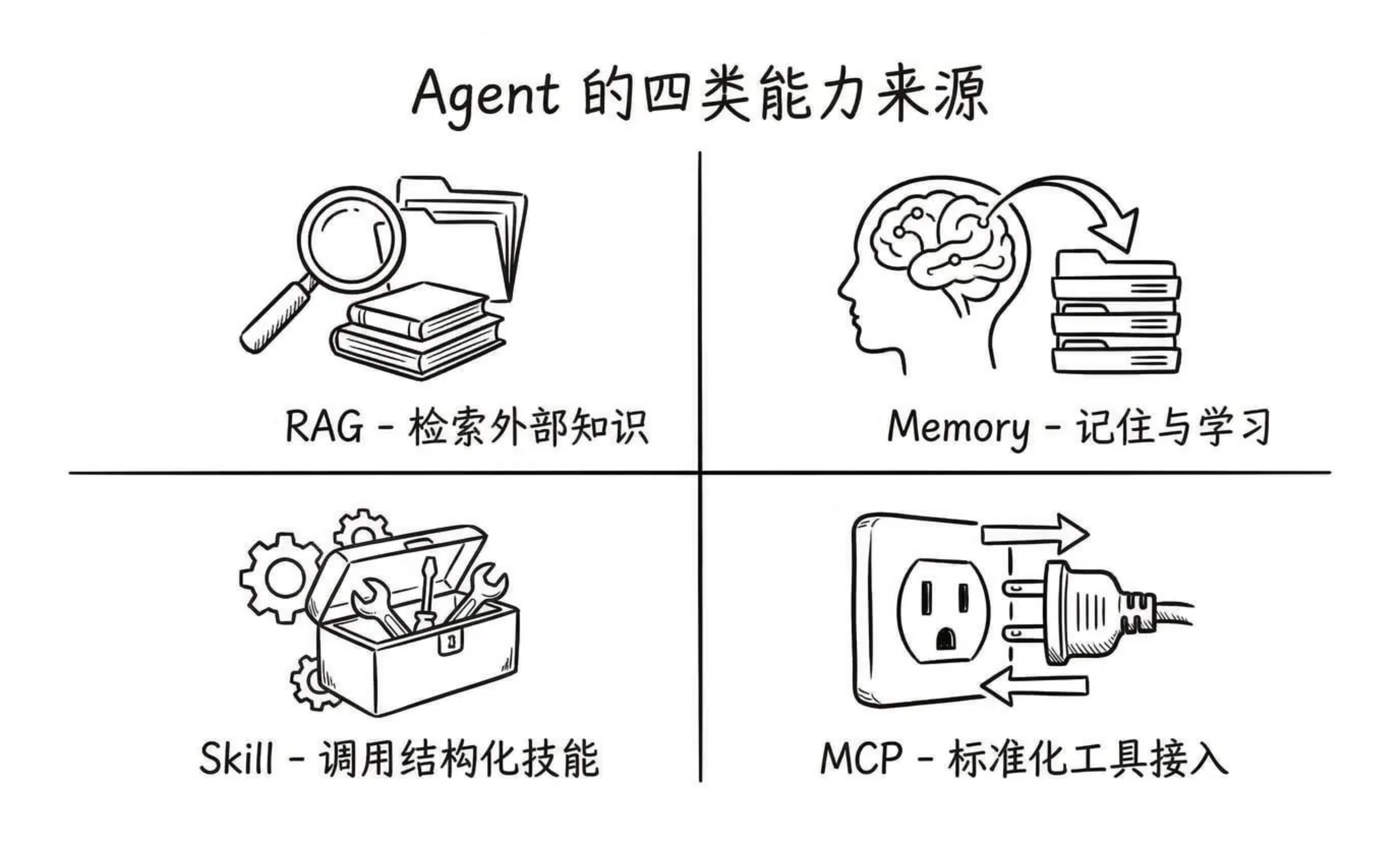
每次刷技术社区是不是觉得这些概念满天飞?别慌,我今天帮大家把它们放到同一张地图上,你会发现它们的底层逻辑惊人地一致。
RAG —— 让 Agent 会「查资料」
让 Agent 能“查资料”:从 Naive RAG 到 Agentic RAG 的演进
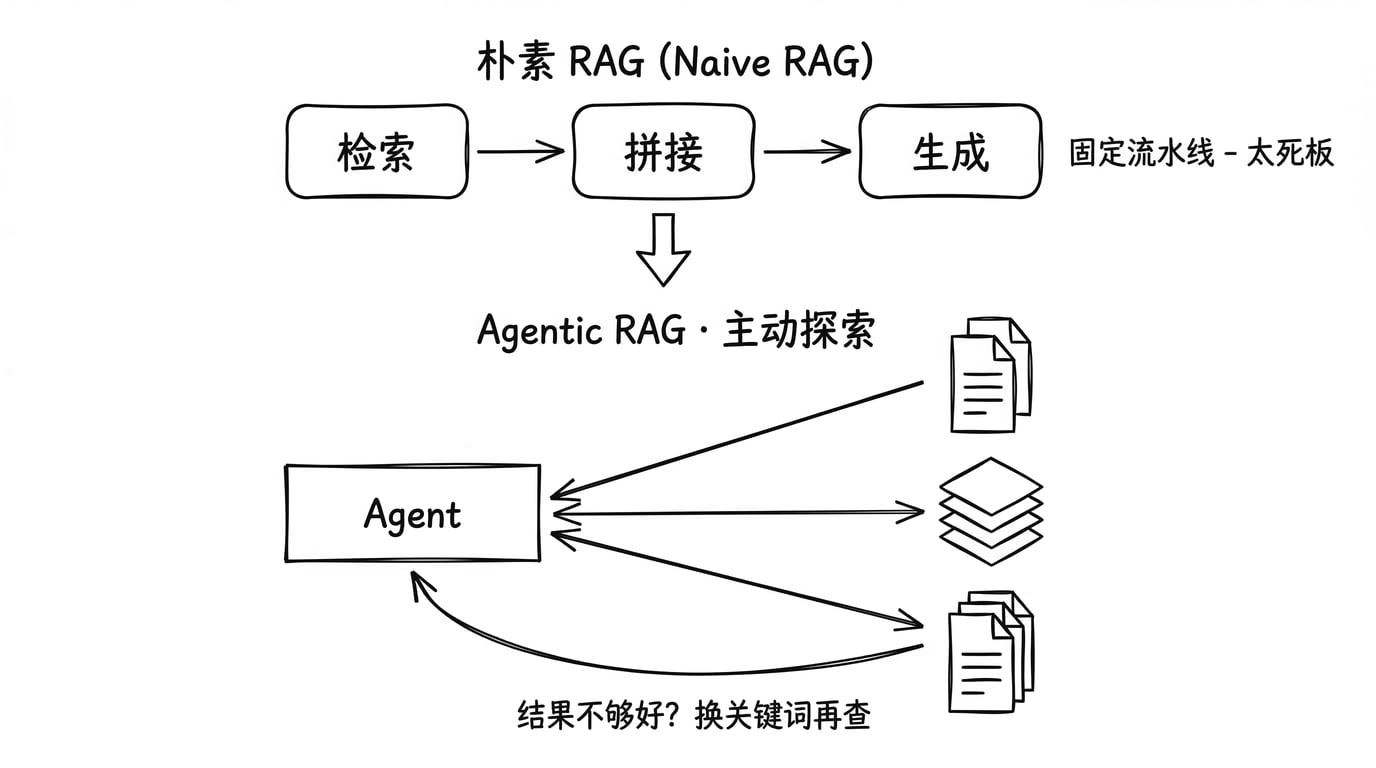
Naive RAG(朴素 RAG):
- 固定流程:检索 → 拼接 → 生成
- 单次检索,结果直接注入 Prompt
- 局限:无法处理复杂查询、无法自适应调整策略
Agentic RAG:
- Agent 主动判断:要不要查?查哪里?查几次?
- 支持多轮检索、策略调整、多源交叉验证
- 从“被动检索”升级为“主动探索”
RAG 的本质:知识数据的检索。
RAG 的效果天花板取决于:
- 知识库的数据质量(文档完整性、更新频率)
- 切分策略(Chunk Size、重叠度)
- 检索策略(纯向量 vs 混合检索)
- Embedding 模型选择
行业共识:不管 RAG 怎么演进,你拆到底会发现,它的效果天花板始终卡在同一个地方 —— 你的知识数据质量。文档切得好不好、embedding 模型选得对不对、检索策略是纯向量还是混合检索 —— 这些全是数据层的活儿。
业界有句话叫「RAG 的 80% 的问题都是数据问题,不是模型问题」,这话一点不夸张。
MCP —— 标准化工具接入
让 Agent 能“连接外部世界”
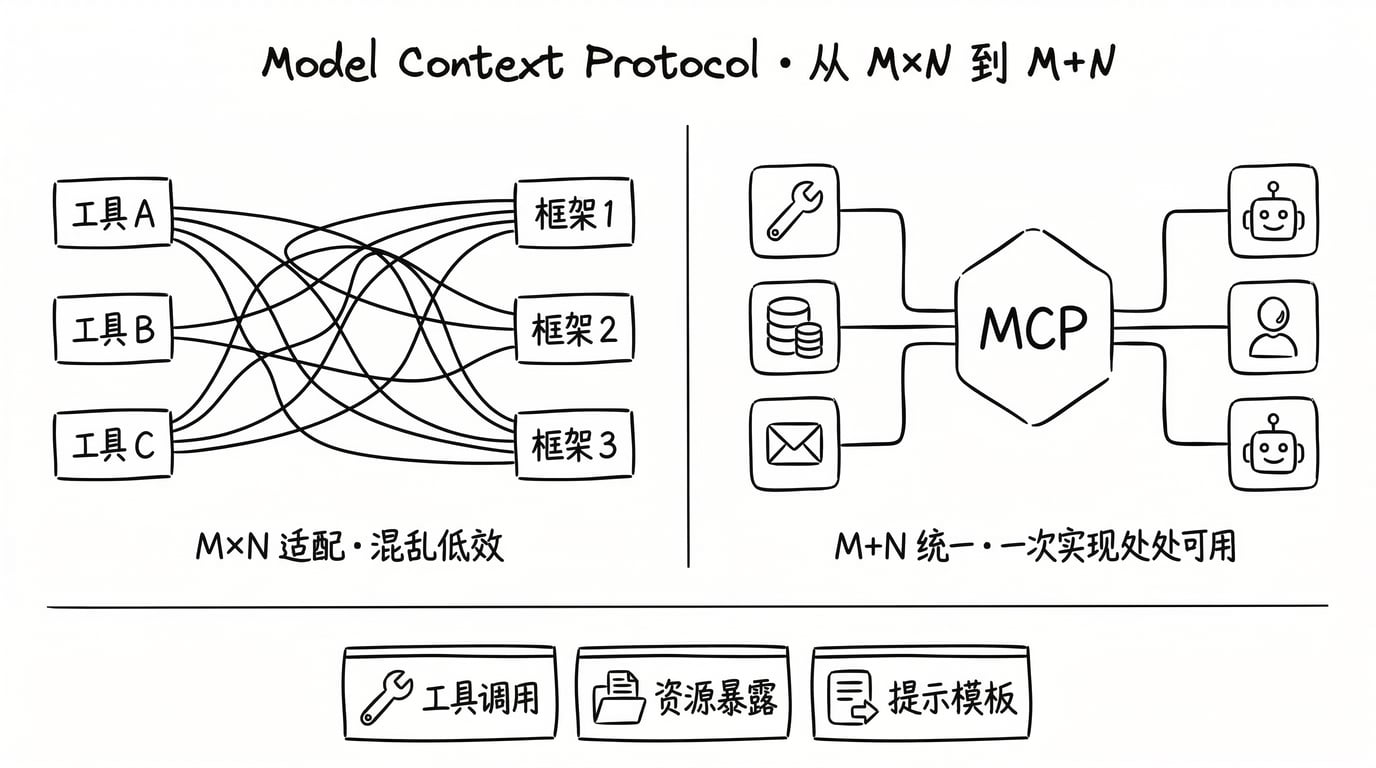
MCP 解决的核心问题
在 MCP(Model Context Protocol)出现之前,Agent 工具接入面临 M×N 集成问题:
- M 个 Agent 框架 × N 个工具 = M×N 种适配方案
- 每个工具需要为每个框架单独开发接口
- 每个框架需要为每个工具单独编写适配代码
MCP 的解决方案:统一协议标准
- 工具侧:实现统一的 MCP Server
- Agent 侧:实现统一的 MCP Client
- 集成复杂度从 M×N 降低到 M+N
类比:MCP 是 AI 工具生态的“USB 接口”
正如 USB 统一了键盘、鼠标、打印机的接口标准,MCP 统一了 AI 工具的接入协议。
MCP 的三大能力:
- Tool Calling:工具调用(执行操作)
- Resource Exposure:资源暴露(读取数据)
- Prompt Templates:提示模板(预设交互)
MCP 的本质:数据接入的标准化。
MCP 解决的不是单个工具的质量问题,而是整个工具生态的互联互通问题。
Skill —— 调用结构化技能
让 Agent 能“会做某件事”
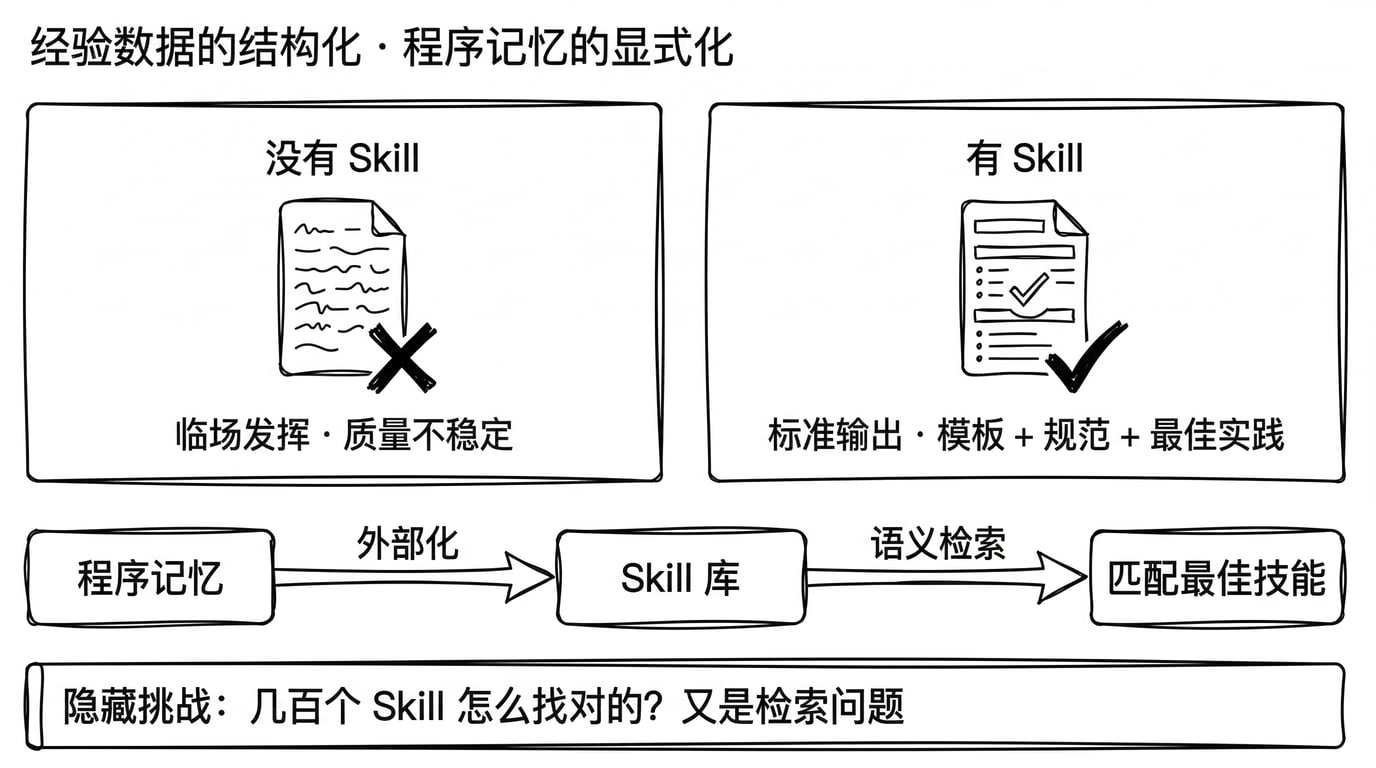
Skill 的本质 是将人类专业经验转化为 Agent 可理解和执行的结构化数据。
组成要素:
- 操作流程(Step-by-step 指令)
- 领域规则(约束条件、质量标准)
- 成功案例(历史优秀输出)
- 术语表(领域特定词汇)
与程序记忆的关系:Skill 是程序记忆的显式化与可复用化。程序记忆是 Agent 在运行中学到的“遇到什么情况该怎么做”, Skill 是将这些经验提前总结并外部化存储。
Skill 的本质:经验数据的结构化。
Skill 的效果取决于:
- 技能结构化程度(是否清晰可执行)
- 发现能力(如何在技能库中检索匹配的 Skill)
- 复用性(跨场景、跨用户的适用性)
Memory —— 个性化数据的积累与召回
让 Agent 能“记住你”
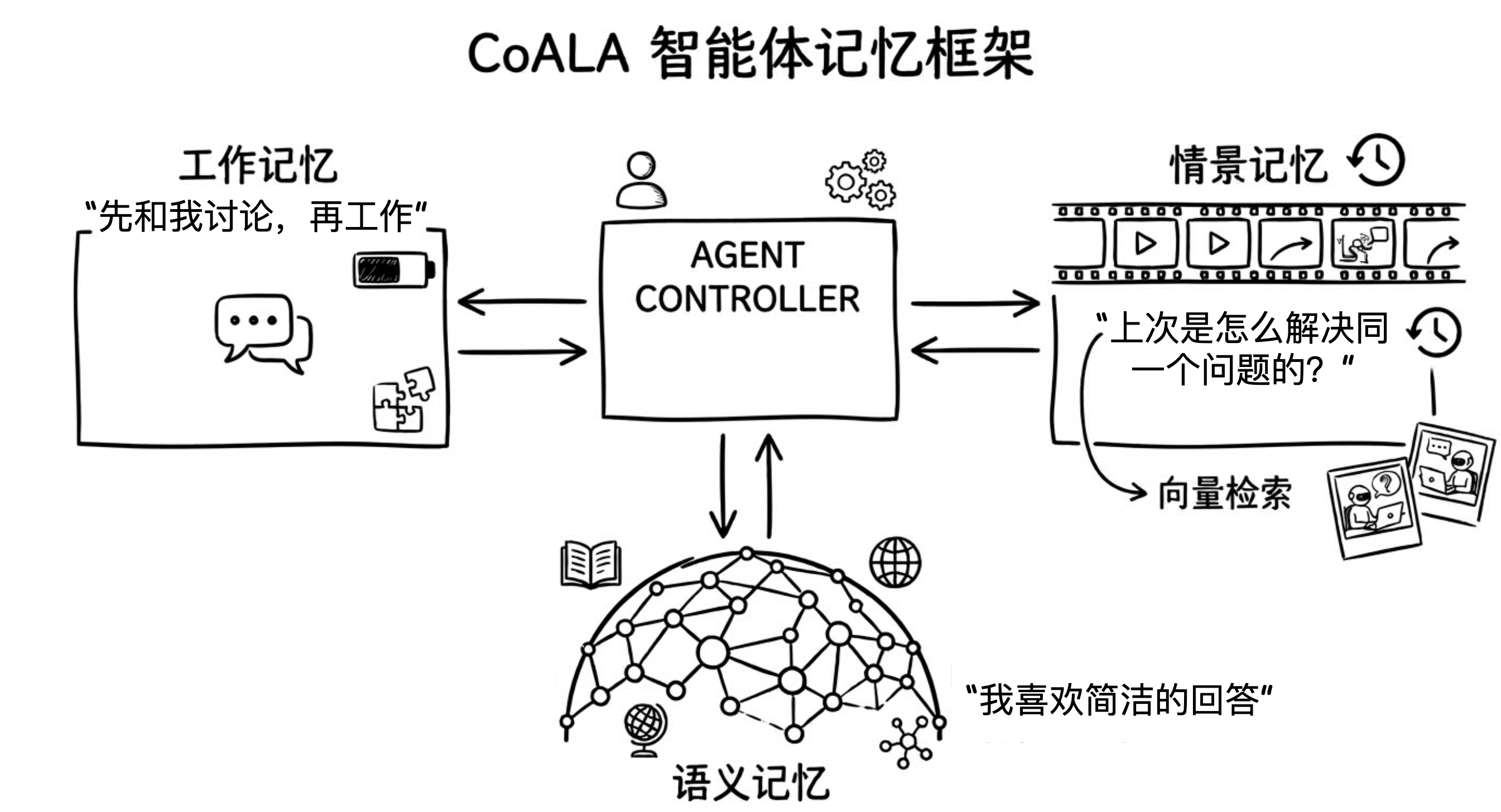
根据 CoALA 论文,Agent 记忆分为三种:
1. 语义记忆(Semantic Memory)
- 记住事实与偏好
- 示例:“用户是 Python 开发者”、“用户偏好简洁回答”
2. 情景记忆(Episodic Memory)
- 记住过往经验
- 示例:“上次用 Docker 方案解决了部署问题”
3. 工作记忆(Working Memory)/ 程序性记忆(Procedural Memory)
- 记住行为规则
- 示例:“遇到代码问题先查文档再写代码”
本质:数据的积累与召回
Memory 的效果取决于:
- 记忆提炼质量(如何从对话中抽取关键信息)
- 召回策略(何时调用哪些记忆)
- 遗忘机制(如何降权过时信息)
本期总结:数据是这一切的基础
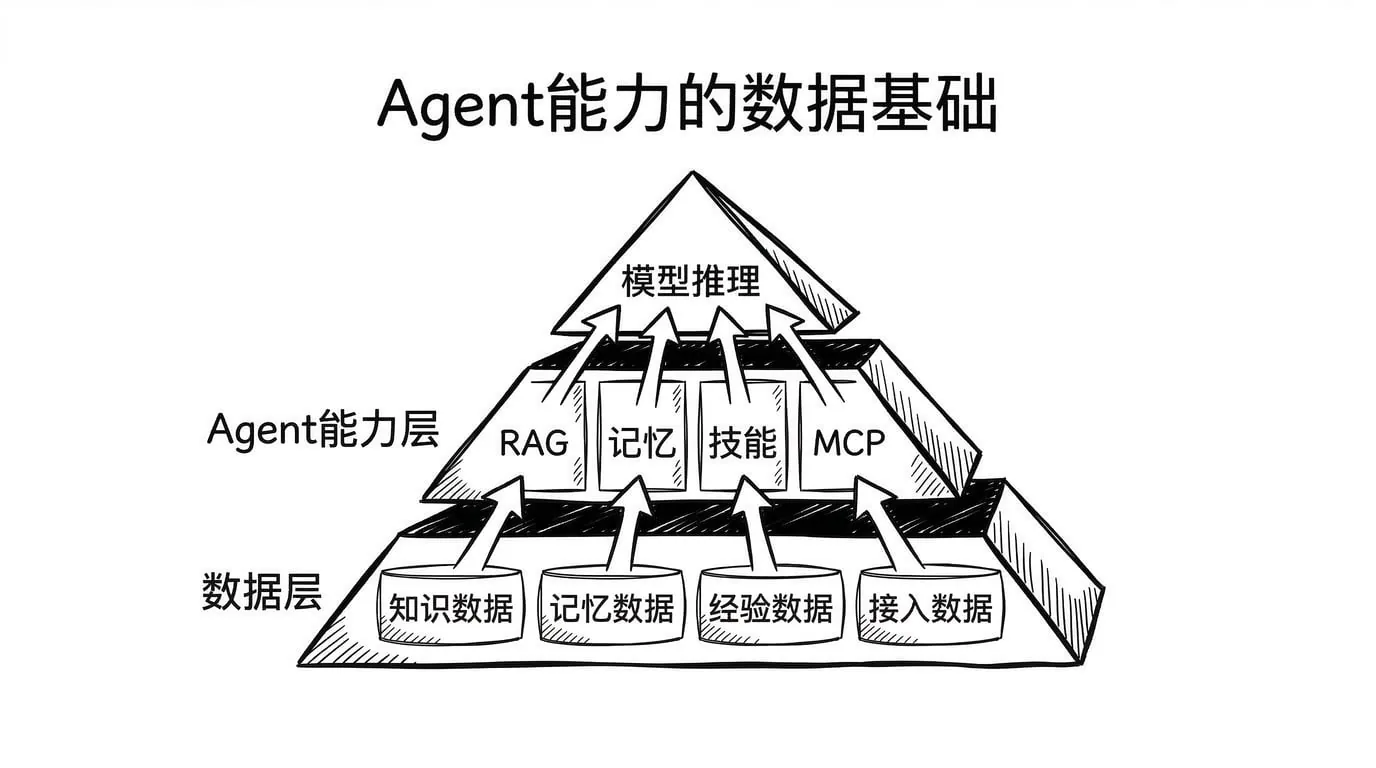
现在,让我们换一个视角重新看这四类能力:
| Agent 能力 | 表面概念 | 数据本质 |
|---|---|---|
| RAG | 检索外部知识 | 知识数据的检索 |
| MCP | 标准化工具接入 | 数据接入的标准化 |
| Skill | 调用结构化技能 | 经验数据的结构化 |
| Memory | 记住与学习 | 数据的积累与召回 |
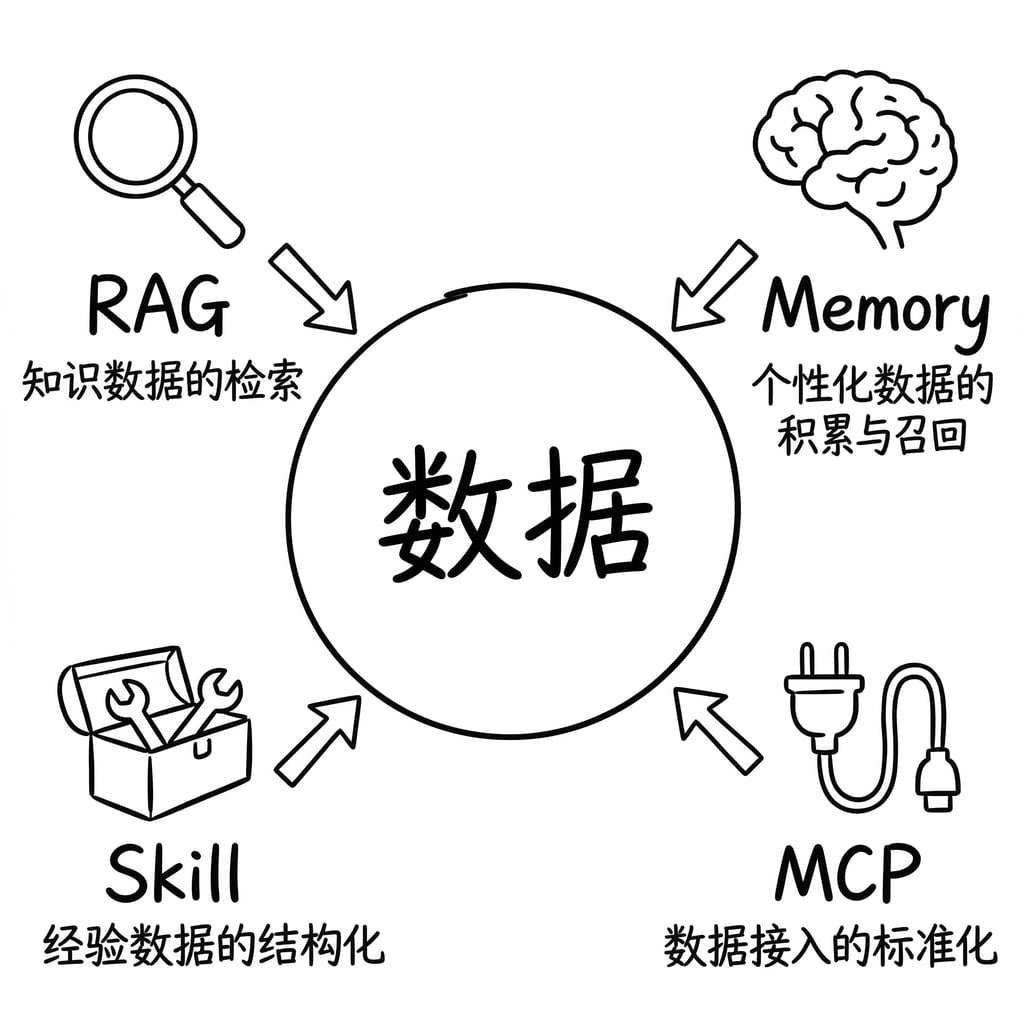
看到了吗?Agent 的每一项能力,拆到底都是在做数据的存储与检索。
- RAG 的效果好不好?
- 取决于知识库的数据质量和检索策略
- MCP 能连接多少工具?
- 取决于数据接口的标准化程度
- Skill 能不能复用?
- 取决于技能的数据结构化程度和检索能力
- Memory 准不准?
- 取决于记忆数据的提炼质量和召回策略
你会发现,行业里这些让人眼花缭乱的热词,拆到底全部指向同一件事 —— 数据。 它们只是在 Agent 架构的不同位置上,用不同的方式在处理数据的存储、检索和流转。
想通了这一点,你就不会被新概念带着跑了。下次再冒出来一个新的 buzzword,你只需要问自己一个问题:它在数据层面解决的是什么问题? 答案往往就清楚了。
希望大家通过这节课程,能够记住一句话:模型决定了 Agent 能“想多好”,数据决定了 Agent 能“做多好”。
我们的思考:AI Agent 时代,亟需统一的数据引擎
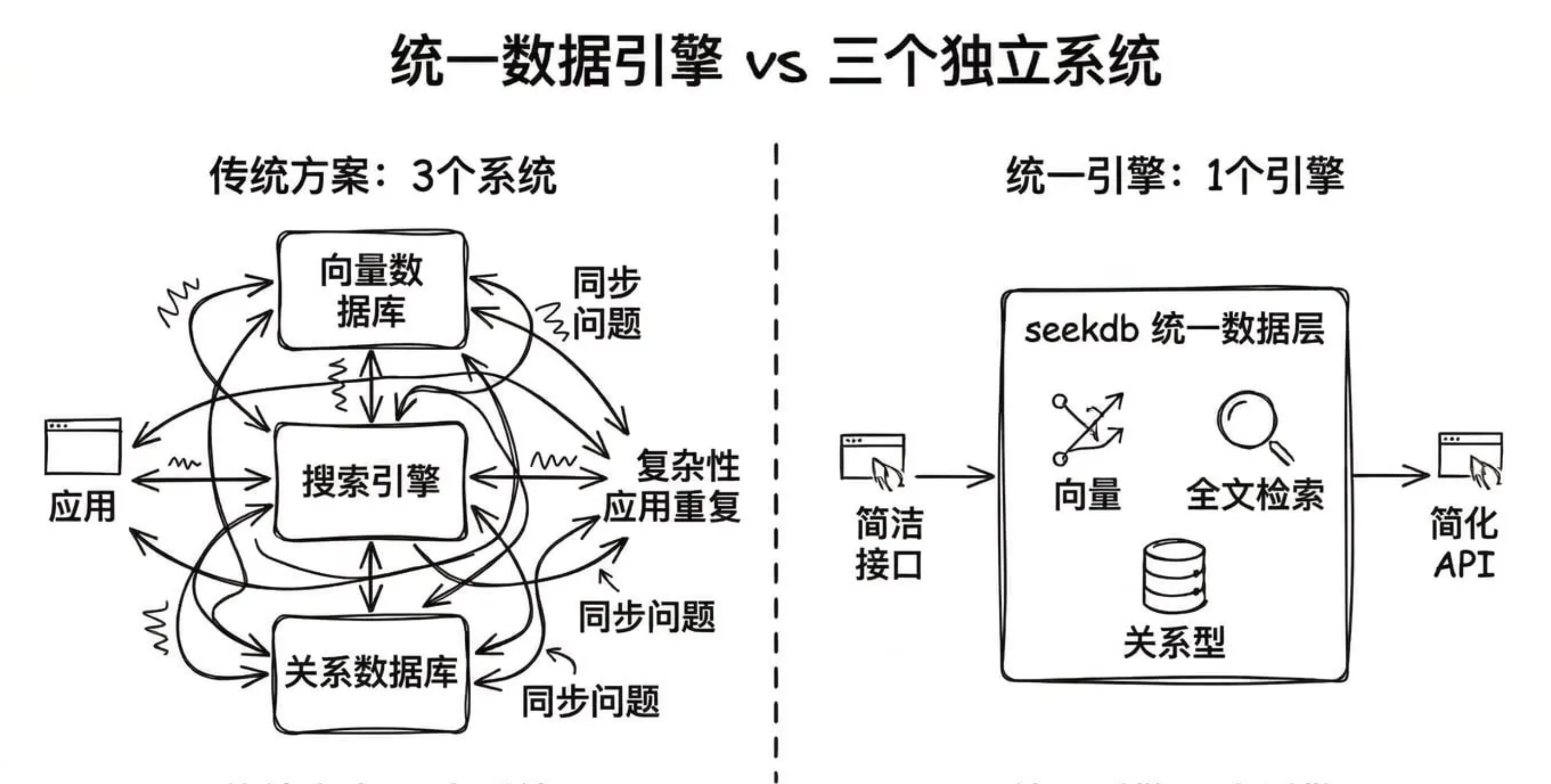
我们通过这张 Agent 能力地图,观察到一个普遍现象:Agent 需要同时处理三种数据:
- 向量数据(语义检索):找“意思相近”的内容
- 全文数据(关键词匹配):找“精确包含”某个词的内容
- 关系数据(结构化查询):按条件过滤(时间、作者、类型……)
传统方案是什么?三套系统各管一摊:
- 向量数据库(Pinecone、Weaviate)管语义检索
- 搜索引擎(Elasticsearch)管关键词匹配
- 关系数据库(PostgreSQL)管结构化查询
然后在应用层写胶水代码,手动协调三个系统的结果。
这不仅增加运维复杂度,还导致检索结果难以有机整合。
我们认为:AI 应用的数据层应该是一个统一的引擎。
因此,我们发布的 seekdb 就是为了这个目的,而为 AI 时代的数据库用户和开发者打造的统一存储 / 计算引擎:一个系统,同时处理向量、全文和关系数据。
除此以外,我们还为大家提供了 PowerMem —— 基于 seekdb 构建的 Agent 记忆系统:把记忆的提炼、检索、遗忘封装成开箱即用的能力。
在后续课程中,作为“我们从实践中观察到的行业问题和思考”,你会看到它们在不同场景下陆续登场~
下期先导预告:道篇(PM 决策) <-> 术篇(Dev 实现)
从这节课之后,Easy Data x AI 课程会被分成 “道篇” 和 “术篇” 两条路径:
- 道篇(P1-P5):关注“哪些数据决策是产品决策”
- 术篇(D1-D5):关注“数据层的工程实现”
但它们讲的是同一件事的两面。
下表会帮助两类学员理解“对方在做什么”:
| Agent 能力 | PM 路径关注的决策 | Dev 路径关注的实现 |
|---|---|---|
| Agentic RAG | 知识库涵盖什么内容? 更新频率?权限设计?(P2) | 混合检索的工程实现 对比实验验证效果(D2-D3) |
| Agent Memory | 记什么、忘什么、给谁看? 信任设计(P3) | 记忆提炼、检索、降权 的代码落地(D4) |
| Skill | 技能如何统一管理? 跨平台复用?(P4) | Skill 文件编写 语义检索发现(D5) |
| MCP | 数据标准化如何影响 产品扩展性?(P4-P5) | MCP Server 配置 与接入(D5) |
| 归因与度量 | 三层归因框架: 数据层/模型层/业务层(P2-P5) | 对比实验: 用数据说话(D3) |
从 Data 视角看预告
接下来的每一期课程,我们都会从 Data 的视角进行拆解:
这个能力的数据需求是什么?
数据从哪来、怎么存、怎么检索?
数据层的设计决策如何直接影响 AI 的最终效果?
道篇(PM 路径,产品决策视角)
- P1:AI Agent 场景识别 → 立项时先问“数据在哪?”
- P2: Agentic RAG 产品设计 → 知识库是产品决策,不只是技术决策
- P3:Agent 记忆系统设计 → 难的不是“存”,而是“该忘什么”
- P4:Skill 与知识管理 → Skill 碎片化本质上是数据管理问题
- P5:综合案例与度量 → 三层度量框架:数据层/模型层/业务层
术篇(Dev 路径,工程实现视角)
- D1:大模型 API 基础 → Tool Use 是 Agent 与数据交互的桥梁
- D2:AI 应用的数据层 → 一个系统搞定,比三个系统拼凑更好
- D3: Agentic RAG 实战 → 亲眼看到混合检索 vs 纯向量检索的差距
- D4:Agent 开发与记忆系统 → 记、忘、想起的数据挑战
- D5:Skill、MCP 与综合项目 → Agent 的一切能力,根基都在数据层
本期总结
RAG、Memory、Skill、MCP 看起来是不同的技术概念,但它们都是 Agent 能力的组成部分,拆到底都是数据问题。
理解了数据,就理解了 Agent 能力的上限在哪。
这张地图会在后续每个模块中反复出现。每次我们讲一个新概念时,你都可以回到这张地图上找到它的位置——以及它和其他概念的关系。
课后行动
画一张你当前产品(或你正在使用的 AI 工具)的能力地图:
- 它有 RAG 吗? → 能查询外部知识吗?知识从哪来?
- 它有记忆吗? → 能记住用户偏好吗?记忆存在哪?
- 它有 Skill 吗? → 能调用预定义的技能吗?技能如何管理?
- 它有 MCP 吗? → 能连接外部工具吗?通过什么协议?
然后问自己:哪些能力缺失?缺失的根源是:
- 数据不存在?
- 数据存在但检索不到?
- 数据格式不对?
这个练习会帮助你建立“系统视角”——把 AI 产品看作一个完整的能力系统,而不是孤立的功能点。
延伸阅读
- CoALA: Cognitive Architectures for Language Agents - Agent 记忆分类框架
- ReAct: Synergizing Reasoning and Acting in Language Models - Agent 推理循环模式
- Model Context Protocol (MCP) - Anthropic 的标准化协议
What's more?
从下周开始,我们会每周为大家更新两期课程。
道篇: → P1:AI Agent 场景识别
术篇: → D1:大模型 API 工程化基础
两条路径从这里分开,但讲的是同一件事的两面。欢迎选择适合你的路径,和我一起继续探索 Data x AI!
最后,欢迎各位老师加入 Data x AI 交流群,和我们一起玩耍~
