F1:AI 必知必会(一)—— 大模型的本质与边界
本期是所有学员的共同起点。无论你是产品经理、开发者、还是 AI 爱好者,这节课的内容会成为后续所有模块的认知基础。
WARNING
🧪 Beta 公测版本提示:本节课程主体已完成,正在优化细节。
欢迎大家提 Issue 反馈问题或建议,也欢迎大家提 Pull Request 参与课程共建。
本期课程简介
欢迎来到 Easy Data x AI 课程。在这节课中,我们将一起探讨大模型的本质与边界。
学习完这节课后,你将能够:
- 识别大模型的三个核心局限及其根本原因。
- 建立“补数据而非换模型”的解题思维。
- 理解大模型如何“理解”和“生成”文字(延伸阅读部分)。
本节课程希望能够为大家建立一个统一的认知基础:
AI 产品的能力上限 = 数据质量 * 模型能力。

接下来,我们正式开始本期课程。
我们希望大家能通过这期课程,消除对大模型的两种常见误解 —— 既不要神话它(它不是万能的),也不要轻视它(它的能力确实很强)。
开门见山
现在几乎所有人都在讨论模型 —— 哪个模型更强、哪个模型更便宜、哪个模型多模态能力更好。
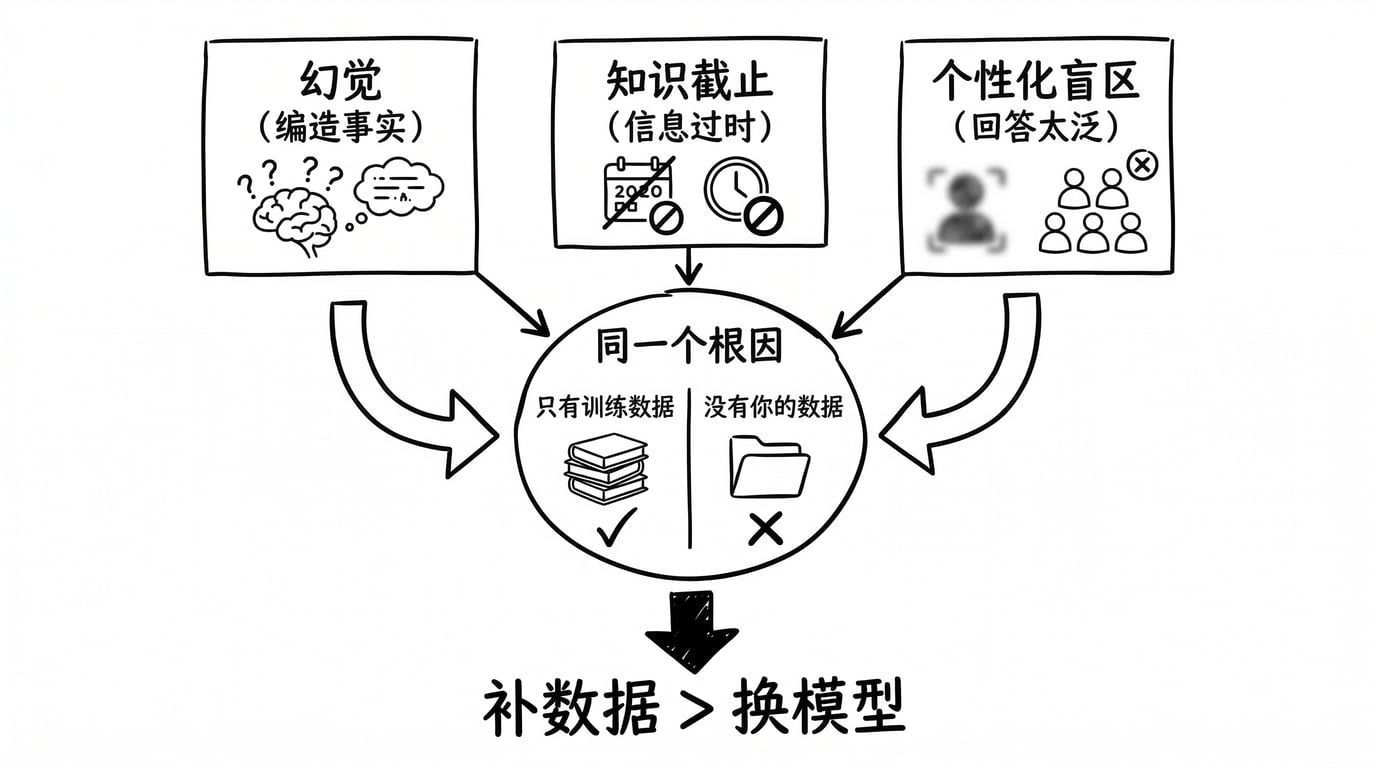
却很少有人意识到:大模型产生这些根本局限的原因,其实是同一个 —— 大模型只有内置的训练数据,但没有你的数据。
接下来我们简单聊下大模型的三个根本局限:幻觉、知识截止、个人化盲区。
大模型为什么会“说谎”?
幻觉:听起来对,但查无此事
什么是“幻觉”?
AI 幻觉(Hallucination)是指大模型生成的内容听起来很合理、很自信,但实际上是错误的或编造的。
用一个比喻来理解:
想象你在玩“接龙游戏”:
- 我说:“天空是”?
- 你根据经验说:“蓝色的”(这在已有能检索到的内容里最常见)。
- 但实际上,此刻窗外正在下雨,天空是灰色的。
大模型不是在“检索事实”,而是在“预测下一个词”
工作原理拆解:
- 训练阶段:模型从海量文本中学习“什么样的文字组合在统计上是合理的”
- 生成阶段:模型根据概率分布,逐个 Token 地预测“接下来最可能出现的词”
- 问题所在:模型生成的是“听起来合理的文字”,而非“经过验证的答案”
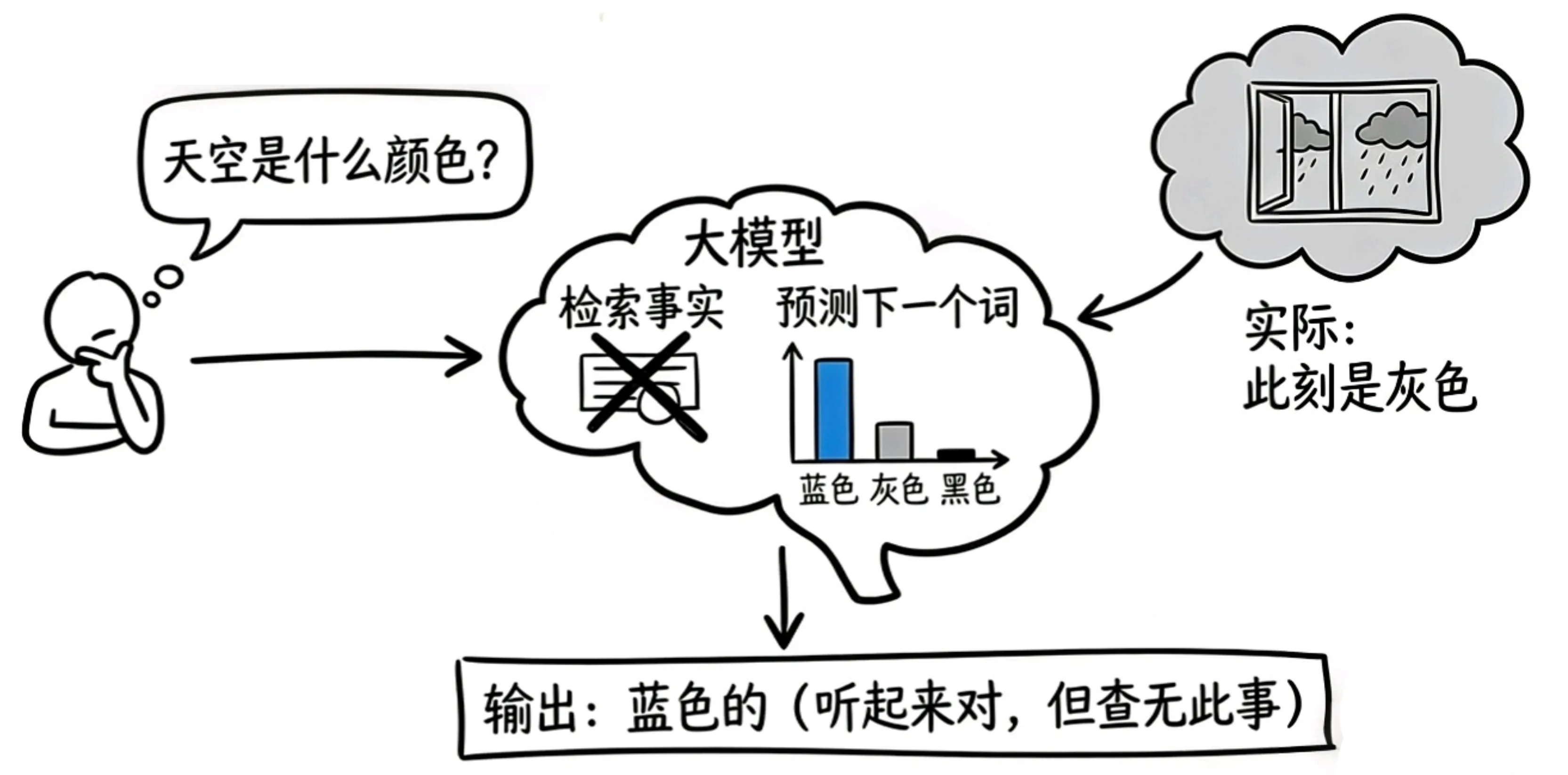
大模型就像这样——它知道“天空通常是蓝色的”(训练数据中的统计规律),但它不知道“此刻窗外的天空是什么颜色”(你的实时数据)。
这就是幻觉的本质:大模型在所有问题上都用同一种方式回答 —— 预测最可能的词。它无法区分“我知道”和“我在猜”。
大模型的知识来源只有一个:训练数据。训练数据里有的,它可能答对;训练数据里没有的,它也会答 —— 但答案是“编造”的。
为什么幻觉不能靠“更好的模型”来解决
这是很多人的直觉反应:模型会出错,那就等一个更好的模型吧?
但幻觉的根因不是“模型不够好”,而是模型缺少数据。一个更聪明的预测机器,面对“训练数据里不存在的事实”,仍然只能猜。它可能猜得更有技巧(比如学会说“我不确定”),但它不可能凭空生成正确答案 —— 因为正确答案不在它的训练数据里。
真正的解法是什么?是把正确的数据给它。让它不用猜,而是有据可查。这正是后续课程会展开的 RAG(检索增强生成)的核心逻辑——先从你的知识库中检索到相关数据,再让模型基于这些数据来回答。
但这是后面的内容。现在你只需要记住一个判断:幻觉问题的根因是缺少可验证的事实数据,不是模型不够聪明。
大模型不知道的那些事
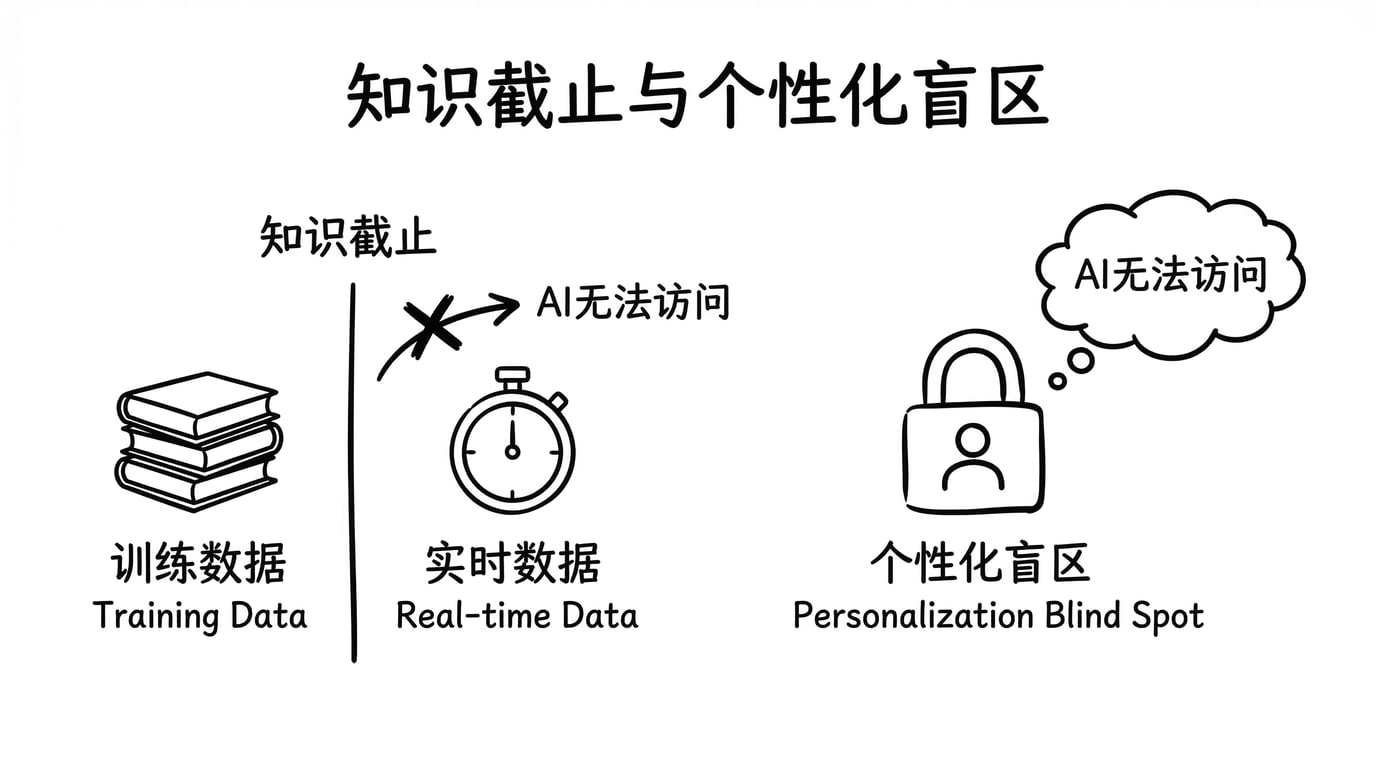
知识截止:它活在过去
每个大模型都有一个知识截止日期(Knowledge Cutoff)。这个日期意味着:在这之后发生的事情,它完全不知道。
比如一个知识截止到 2026 年 2 月的模型:
- 问它“2026 年 1 月发布了哪些重要的 AI 论文” —— 它可能答得不错。
- 问它“2026 年 3 月最新的行业动态” —— 它要么说“我不知道”,要么编一个(回到幻觉问题)。
你可能会想:模型厂商不断更新训练数据不就行了?确实,主流模型的知识截止日期在不断推后。但这里有一个根本性的时间差 —— 从事件发生到被纳入训练数据,永远有滞后。今天发布的一份行业报告、今天更新的一份产品文档、今天客户提出的一个新问题 —— 这些信息不可能立刻出现在任何模型的训练数据里。
对于需要实时信息的应用场景,知识截止是一个无法靠“等模型更新”来解决的结构性问题。
个性化盲区:它不认识你
这是大模型最容易被忽视、但产品影响最大的局限。
大模型的训练数据来自公开互联网 —— 书籍、论文、网页、代码仓库。这意味着它知道很多公共知识,但完全不知道:
- 你公司的内部文档:产品规格、操作手册、内部流程。
- 你用户的个人偏好:喜欢简洁回答还是详细解释、是技术背景还是非技术背景。
- 你业务的专有知识:行业术语的特定含义、内部编号系统、历史决策记录。
当你觉得 AI 助手“不够懂我”、“回答太泛”、“没有针对性”的时候,大多数情况下不是模型的理解能力不足,而是它根本没有关于你的数据。
用一个读过十万本书的人来类比:他博学多才,但他从来没在你的公司工作过一天。你问他“我们产品下个版本应该优先做哪个功能”,他能给你一些通用的产品方法论建议,但他不了解你的用户反馈数据、你的技术债务现状、你的竞争对手刚刚发布了什么。这些你的数据,他从未接触过。
总结一下
知识截止的根因是什么?是缺少实时数据。
个性化盲区的根因是什么?是缺少用户数据和业务数据。
和幻觉一样,这两个问题都不是模型能力的问题 —— 模型的推理能力可能已经足够强了,它们都是数据缺失的问题。
三个局限,同一个根因
现在让我们把大模型的这三个局限放在一起看:
| 局限 | 表现 | 根因 |
|---|---|---|
| 幻觉 | 回答听起来合理,但事实有误 | 缺少可验证的事实数据 |
| 知识截止 | 不知道最新发生的事 | 缺少实时数据 |
| 个性化盲区 | 回答正确但不够针对性 | 缺少用户数据和业务数据 |
看似三个不同的问题,实则指向同一个根因:
大模型只有训练数据,没有你的数据。
幻觉是因为训练数据里缺少你需要的那个确切事实;知识截止是因为训练数据更新不够快;个性化盲区是因为训练数据里根本没有关于你、你的用户、你的业务的信息。
理解了这个根因,解题思路就变得清晰了:
不是等一个更好的模型,而是补上缺失的数据。
- 产生幻觉 → 给模型提供可检索的事实数据(后续课程的 RAG 模块会展开)。
- 知识截止 → 给模型接入实时更新的数据源。
- 个性化盲区 → 给模型提供用户数据和业务数据(后续课程的记忆系统模块会展开)。
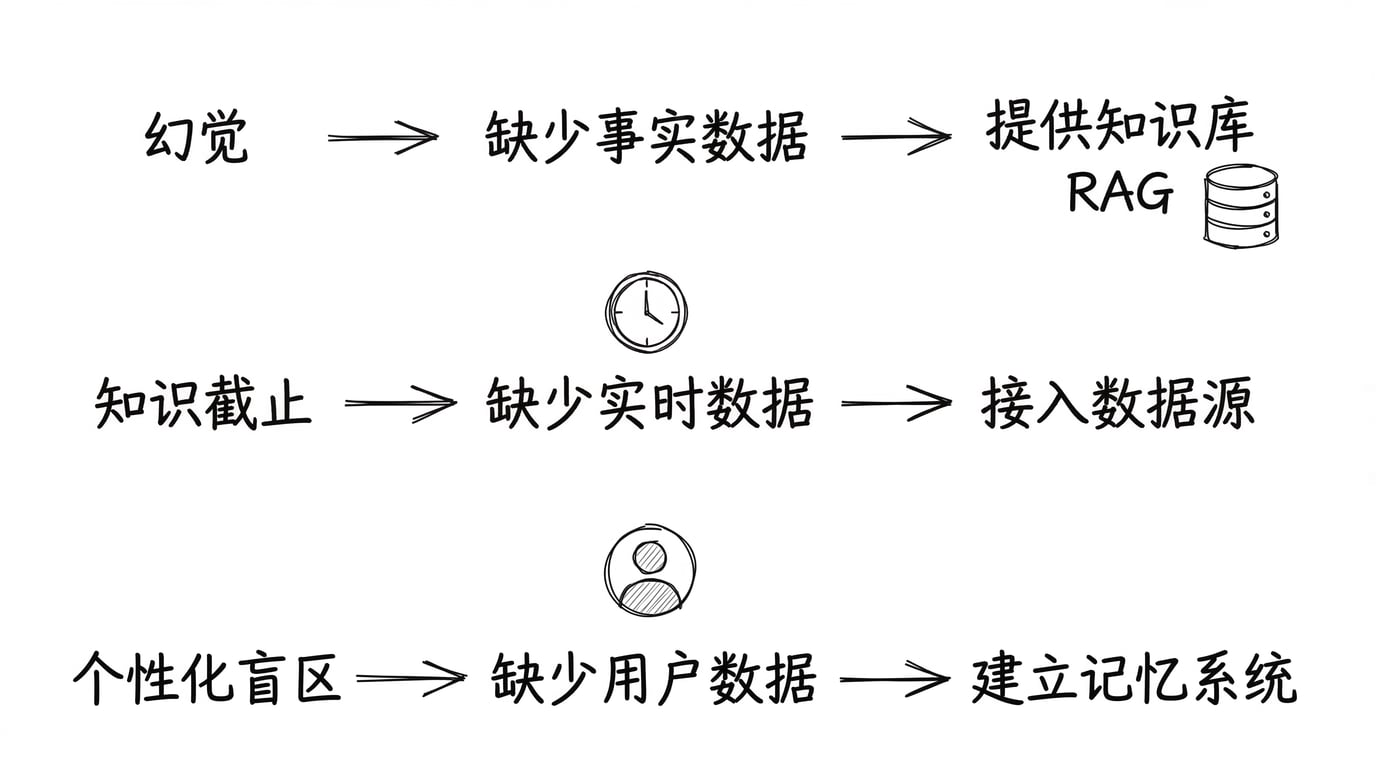
这正是这门课程的核心视角 —— Data x AI。AI 的能力上限,不只取决于模型有多聪明,更取决于它能拿到什么样的数据。
AI 的能力上限 = 数据质量 × 模型能力课程回顾
学完这节课,当你再遇到“AI 不好用”的时候,要试着不要直接“换个更好的模型”,而是先问自己三个问题:
1. 它缺的是哪种数据?
| AI 的表现 | 可能缺的数据 | 解题方向 |
|---|---|---|
| 回答了,但关键细节是错的 | 可验证的事实数据 | 提供可检索的知识库 |
| 说“我不知道”或给了过时信息 | 实时数据 | 接入最新数据源 |
| 回答正确但太泛、不针对 | 用户/业务数据 | 建立用户画像和记忆系统 |
2. 这个问题在模型层还是数据层?
如果换一个模型,问题能解决吗?如果一个更聪明的模型面对同样的数据缺失仍然会出错,那问题就不在模型层。把预算花在模型升级上,不会有效果。
3. 数据能补吗?
数据存在但模型拿不到?那就需要建一个让模型能检索到它的系统。数据根本不存在?那就需要先解决数据采集和整理的问题——这可能是一个产品决策,而不是技术决策。
这三个问题,就是贯穿整个课程的思考框架。后续每个模块,无论是 RAG、记忆系统、Skill 还是 MCP —— 我们都会从同一个角度去拆解:这个能力的数据需求是什么?数据从哪来、怎么存、怎么检索?数据层的设计决策如何直接影响 AI 的最终效果?
本期总结
如果这节课的所有内容你只记住一句话,那就是:
大模型的三个局限,本质上是同一个问题 —— 它只有训练数据,没有你的数据。很多时候,补数据,而非换模型,才是真正解题思路。
下期课程先导预告
下期课程是《AI 必知必会(二) —— AI Agent 全景图》。
我们将为大家展示并介绍 AI Agent 的完整图景 —— 通过一张地图,把 Memory(RAG) 和 Tools(Skill、MCP) 放到正确的位置上,看清它们的关系。并带大家一起去理解这张地图上的每一项能力,底层都和数据有着什么密切的关系。
延伸阅读
Token:大模型眼中的文字
大模型并不像人类那样直接理解“文字”。它理解的是 Token —— 文本的最小处理单位。
简单理解:
- 在英文中,一个 Token 大约是 0.75 个单词(例如 “understanding” 可能被切分为 “under” 和 “standing” 两个 Token)。
- 在中文中,一个汉字通常对应 1-2 个 Token。
- 标点符号、空格也会占用 Token。
你不需要记住 Token 的具体切分规则。只需要理解一件事:大模型处理信息的基本单位不是“字”或“词”,而是 Token。后面我们讨论的很多限制,根源都和 Token 有关。
为什么 Token 这个概念很重要?
因为大模型的所有能力都建立在 Token 之上:
- 模型的“阅读能力”受限于它能处理多少 Token。
- 模型的“记忆能力”受限于它能同时“看到”多少 Token。
- 模型的“推理能力”受限于它能同时“处理”多少 Token。
- API 的计费通常按 Token 数量计算。
上下文窗口:大模型的“视野范围”
想象你在读一份很长的报告,但你的桌子只能摊开 20 页纸。如果报告有 100 页,你一次只能看其中的 20 页——要看后面的内容,就必须把前面的纸挪走。
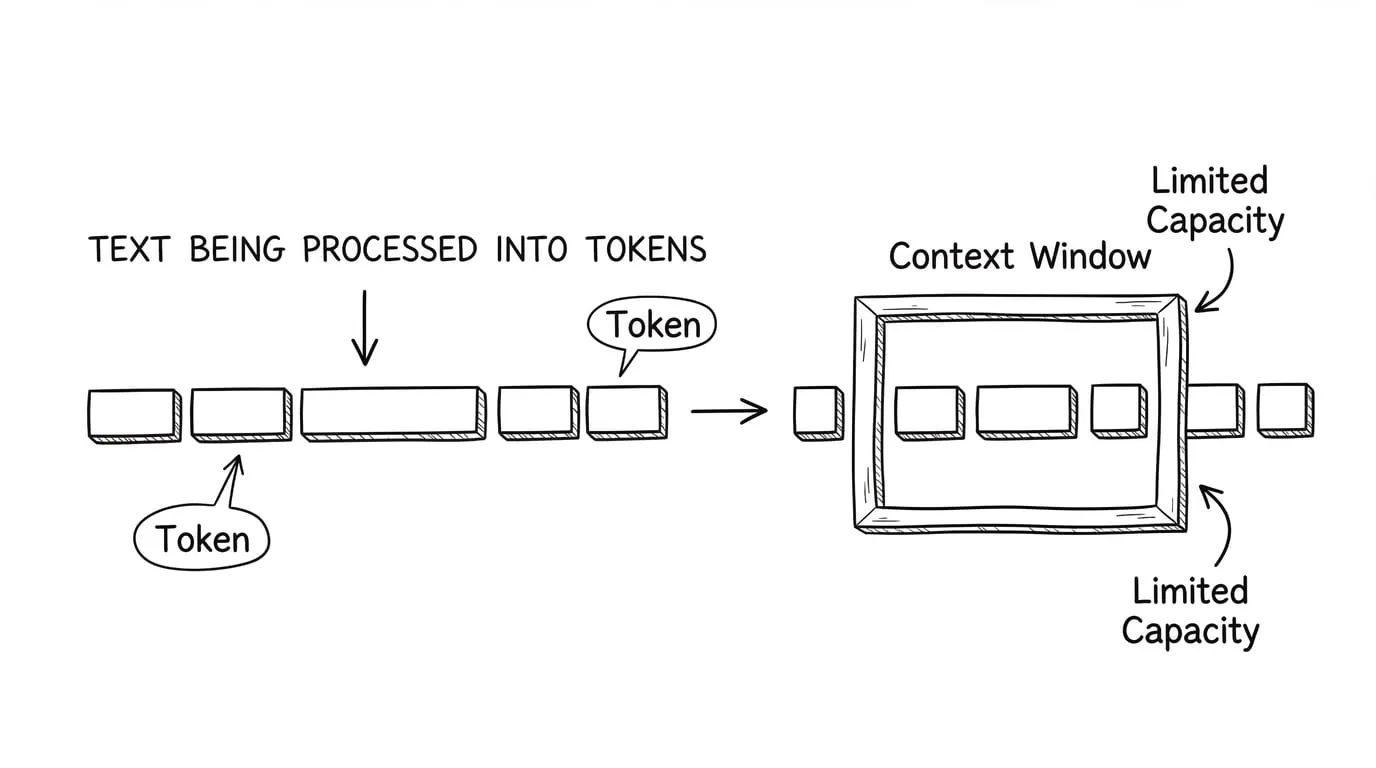
大模型面临着完全相同的限制。它有一个“上下文窗口”(Context Window),决定了它一次能处理多少 Token。目前主流大模型的上下文窗口大小:
| 模型 | 上下文窗口 | 大约相当于 |
|---|---|---|
| GPT-4o | 128K Token | ~200 页文档 |
| Claude 4 Sonnet | 200K Token | ~300 页文档 |
| Gemini 2.5 Pro | 1M Token | ~1500 页文档 |
看起来窗口在快速变大,200 页甚至 1500 页已经不小了。
但这里有一个关键认知:上下文窗口再大,它也只是“一次性”的。每次新的对话开始,窗口就清空了。你上次告诉 AI 的所有信息——你的名字、你的偏好、你的项目背景 —— 全部消失。它不是忘了,而是它根本没有地方存这些信息。
这意味着什么?意味着大模型天生是一个没有记忆的系统。它的“聪明”只存在于当前这一次对话的窗口之内。要让它在不同对话之间记住你、理解你,靠模型本身是做不到的 —— 你需要在模型之外,为它建立一个数据系统。
关键洞察:
上下文窗口的限制是后续所有 AI 架构设计的根本动因。正是因为模型不能“一次看完所有内容”,我们才需要:
- RAG(检索增强生成):从大量文档中检索最相关的部分,放入上下文窗口。
- 记忆系统:从历史对话中提炼关键信息,选择性地放入上下文窗口。
- Agent 架构:让模型分步骤处理复杂任务,而不是一次性处理所有信息。
记住这一点:上下文窗口不是技术细节,而是理解 AI 应用架构的基础。后续课程中的每一个设计决策,都和这个限制有关,这也是后续课程要解决的核心问题之一。
其他
如果你还希望对本期提到的概念想做进一步了解,以下是一些推荐资源:
- Token 与 Tokenizer:OpenAI 提供了一个在线工具 Tokenizer,可以直观看到任意文本被切成了哪些 Token。
- 上下文窗口的演进:从 GPT-3 的 4K Token 到 Gemini 2.5 Pro 的 1M Token,窗口在两年内扩大了 250 倍。但窗口变大不等于问题解决——“能放下”和“能有效利用”是两回事,这是后续进阶课程会展开的话题。
- 大模型幻觉的学术综述:Survey of Hallucination in Natural Language Generation,系统梳理了幻觉的分类与成因。
课后行动
找一个你最近用 ChatGPT、Claude 或其他 AI 工具回答不好的问题。然后判断:
- 它缺的是哪种数据?
- 可验证的事实数据?(它编了一个不存在的答案)
- 实时数据?(它给了过时的信息)
- 关于你的个人/业务数据?(它的回答太泛,不够针对性)
- 如果你把正确的数据直接贴进对话里,它能答对吗?(大概率能——这就证明问题不在模型,而在数据)
把你的分析结果带到下节课。
下一期,我们会在这个基础上展开一张完整的地图——看看当前所有热门的 AI 概念(RAG、Memory、Skill、MCP)如何围绕“数据”这个核心组织起来,以及它们之间的关系是什么。
下期课程预告:
我们将为大家展示并介绍 AI Agent 的完整图景 —— 通过一张地图,把 Memory(RAG) 和 Tools(Skill、MCP) 放到正确的位置上,看清它们的关系。并带大家一起去理解这张地图上的每一项能力,底层都和数据有着什么密切的关系。
欢迎各位继续关注下期课程!
最后,欢迎各位老师加入 Data x AI 交流群,和我们一起玩耍~
